The sections below are taken from the slides I used for a talk at the Alliance Francaise de Penang in December 2019. I am grateful to the director and team at the AF for the opportunity to make this presentation.
The fundamental question
We have at least two different pictures of the cosmos and no obvious means of integrating them. We have no intuitive understanding of the micro-scale of physics and chemistry, only a set of mathematical models. But, at the same time, those mathematical models have nothing to say about the familiar world of our own experience of being and the macro-scale world in which we live and which we navigate on a daily basis. So, the question becomes, is there a way to integrate the scientific image of the world with our own experience of existence without compromising either?
You can't understand what that means, without mathematics
Questioner: Roger, how accurately does math describe the physical world?
Roger Penrose: Well it is extraordinarily precise, but I think people often find it puzzling that something abstract as mathematics could really describe reality as we understand it….
I mean reality… you think of something like a chair or something you know, something made of solid stuff, and then you say… well, what’s our best scientific understanding of what that is? Well, you say, it’s made of fibres and cells, and so on… and these are made of molecules, and those molecules are made of atoms, those atoms are made out of nuclei and electrons going around, and you say well… what’s a nucleus? Then you say… well it’s protons and neutrons, and they’re held together by things called gluons… and neutrons and protons are made of things called quarks, and so on.
And then you say, well what is an electron? And what’s a quark? And at that stage, the best you can do is to describe some mathematical structure… you say, they’re things that satisfy the Dirac equation, or something like that… which you can’t understand what that means, without mathematics.”
Roger Penrose: Is Mathematics Invented or Discovered? Closer to the Truth, YouTube Note: Shortened quote
Familiar experience
In normal circumstances, when we are awake and alert, without fuss or deliberation, the images that flow in the mind have a perspective – ours. We spontaneously recognise ourselves as the subjects of mental experiences…we each appreciate mental contents in a distinct perspective, mine or your…
The term “consciousness” applies to the very natural but distinctive kind of mental state described by the above traits. That mental state allows its owner to be the private experiencer of the world around and, just as important, to experience aspects of his or her own being…
It is tempting to simply talk about “subjectivity” and leave behind the term “consciousness” and the distractions it tends to cause. We should resist the temptation, because the term “consciousness” conveys an additional and important component of conscious states: integrated experience, which consists of placing mental contents into a more or less unified multidimensional panorama. In conclusion, subjectivity and integrated experience are the critical components of consciousness.
Antonio Damasio: The Strange Order of Things
Entities and events: the dancer and the dance
It all starts with the Pythagoreans. The argument took the shape “Do you ask what it is made of – earth, fire, water, etc?” Or do you ask, “What is its pattern?”
Gregory Bateson: Form, Substance & Difference
O chestnut tree, great rooted blossomer, Are you the leaf, the blossom or the bole? O body swayed to music, O brightening glance, How can we know the dancer from the dance?
WB Yeats: Among School Children (last lines)
The scientific world-view
The idea that the basic laws are the laws about the smallest things has been central to the ‘scientific world-view’ ever since there started to be one. On the other hand, as far as I can see, it’s not any sort of a priori truth. I suppose one can imagine a world where all the big things are made out of small things, and there are laws about the small things and there are laws about the big things, but some laws of the second kind don’t derive from any laws of the first kind.
Jerry Fodor: London Review of Books
Our reality is composed of entities and events at different scales
If length may serve as a proxy, the subatomic scale lies roughly between 10-35 to 10-18 metres. Between 10-18 and 10-9 is the scale of atoms and molecules and around 10-6 is the scale of cells and micro-organisms. The spectacular diversity of structures that is familiar to us broadly occupies a range from 10-4 (10ths of a millimetre) up to around 106 (1,000s of kilometres). At a much larger scale there is the astronomical scale reaching from moons and planets to stars and galaxies.
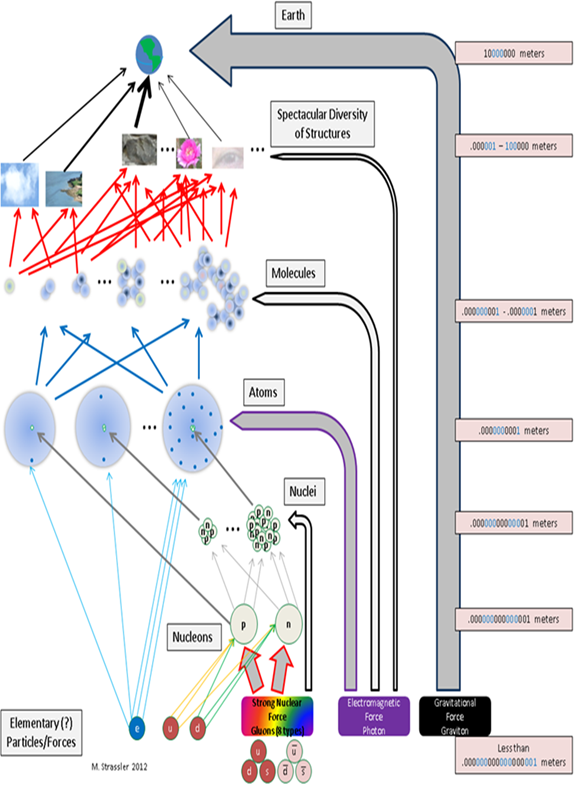
https://profmattstrassler.com/tag/nytimes/
A theory is just a model
A theory is just a model of the universe…and a set of rules that relate quantities in the model to observations that we make. A theory is a good theory if it satisfies two requirements: it must accurately describe a large class of observations on the basis of a model that contains only a few arbitrary elements, and it must make definite predictions about the results of future observations.
Stephen Hawking: A Brief History of Time
We might think of a model as a structure that is intended to represent another structure by virtue of an abstract similarity relationship between them… A good model is one that has some kind of similarity relationship, probably of an abstract kind, with the system that the model is “targeted” at.
Peter Godfrey-Smith: Theory & Reality
Physical theories are essentially mathematical in nature
Physical theories, insofar as they make empirically falsifiable predictions, are essentially mathematical in nature. The mathematical formalism of quantum mechanics, for example, makes predictions regarding the quantitative (i.e., mathematical) results of measurements. These predictions of the mathematical formalism either match actual quantitative experimental results or they do not. If they match, the mathematical formalism stands confirmed. If they do not, the formalism is falsified. In this sense, the scientific knowledge of the universe provided by physics is essentially mathematical in both theory and experiment.
Now, the formalism of a physical theory may be interpreted in various ways. But these philosophical interpretations are not, strictly speaking, part of the empirically falsifiable knowledge provided by physics…Expunging all natural philosophy and interpretation from physics, however, is unnecessary. It is sufficient to clearly recognize and distinguish the scientific knowledge that it provides, which is essentially mathematical, from the speculative philosophical interpretations that are attached to the mathematical formalism.
Tom McFarlane: contributor to Quora
What distinguishes a living system?
There is, however, a more serious objection to the idea that biological structures are self-organised. Structures such as [a splash pattern] differ from biological structures in one crucial respect: they may be complicated, but they are not adapted to ensure their own survival and reproduction. It is this apparent design for survival that distinguishes living structures (and human artefacts) from non-living ones. An eye is designed for seeing: a vortex merely exists.
John Maynard-Smith: Shaping Life
The continuity of life
In brief, the assembly of what became feelings and consciousness for us was made gradually, incrementally, but irregularly, along separate lines of evolutionary history. The fact that we can find so much in common in the social and affective behaviours of single-celled organisms, sponges and hydras, cephalopods, and mammals suggests a common root for the problems of life regulation in different creatures and also a shared solution: obeying the homeostatic imperative.
Antonio Damasio: The Strange Order of Things
Human exceptionalism - the inner life
At this point the meaning of the concepts inner and outer and the justification for using them becomes clear. They designate the relationship which exists in the understanding between the outer phenomena of life and what produces them and is expressed in them. The relationship between inner and outer exists only for understanding, just as the relationship between phenomena and that by which they are explained exists only for scientific cognition.
Wilhelm Dilthey: The Construction of the Historical World in the Human Studies
In conclusion, subjectivity and integrated experience are the critical components of consciousness…subjectivity and consciousness are essential enablers of the cultural mind. In the absence of subjectivity, nothing matters; in the absence of some degree of integrated experience, the reflection and discernment that are required for creativity are not possible.
Antonio Damasio: The Strange Order of Things
Rationality and the coherence of the story
The measure of success for System 1 is the coherence of the story it manages to create. The amount of quality of the data on which the story is based is are largely irrelevant. When information is scare, which is a common occurrence, System 1 operates as a machine for jumping to conclusions.
Keith Stanovich draws a sharp distinction between two parts of System 2 – indeed, the distinction is so sharp that he calls them separate “minds”. One of these minds (he calls it algorithmic) deals with slow thinking and demanding computation…However, Stanovich argues that high intelligence does not make people immune to biases. Another concept is involved which he labels rationality. The core of his argument is that rationality should be distinguished from intelligence…in his view, superficial or “lazy” thinking is a flaw in the reflective mind, a failure of rationality.
Daniel Kahneman: Thinking, Fast and Slow
Some initial conclusions
So, the question becomes, is there a way to integrate the scientific image of the world with our own experience of existence without compromising either?
I don’t think so, but we can eliminate the idea that there is a necessary conflict.
Firstly, we must remember that every idea is an abstraction. We never apprehend the totality of things.
Secondly, we have no reason to suppose that reality has only one organizing principle. We shouldn’t seek to impose an unnecessary unity on reality.
Thirdly, we need to recognize the biases in the way we think. We can’t necessarily change these, but we can compensate for them.